Reading files and basic introduction
Bill Perry
2018/03/14
Load Libraries
# load the libraries each time you restart R
library(tidyverse)
library(lubridate)
library(readxl)
library(scales)
library(skimr)
library(janitor)
library(patchwork)Read in the file
# Read in file using tidyverse code-----
mm.df <- read_csv("data/mms.csv")##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## center = col_character(),
## color = col_character(),
## diameter = col_double(),
## mass = col_double()
## )Read in excel files
Note that you can read in excel files in the same way.
# Note you can read in excel files just as easy
mm_excel.df <- read_excel("data/mms.xlsx")Look at dataframe structure
One way is to click the blue trianlge in the environment tab in the upper right
You can also use code to inspect the structure of the dataset
# data Structure
str(mm.df)## spec_tbl_df [816 × 4] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ center : chr [1:816] "peanut butter" "peanut butter" "peanut butter" "peanut butter" ...
## $ color : chr [1:816] "blue" "brown" "orange" "brown" ...
## $ diameter: num [1:816] 16.2 16.5 15.5 16.3 15.6 ...
## $ mass : num [1:816] 2.18 2.01 1.78 1.98 1.62 2.59 1.9 2.55 2.07 2.26 ...
## - attr(*, "spec")=
## .. cols(
## .. center = col_character(),
## .. color = col_character(),
## .. diameter = col_double(),
## .. mass = col_double()
## .. )# or
glimpse(mm.df)## Rows: 816
## Columns: 4
## $ center <chr> "peanut butter", "peanut butter", "peanut butter", "peanut bu…
## $ color <chr> "blue", "brown", "orange", "brown", "yellow", "brown", "yello…
## $ diameter <dbl> 16.20, 16.50, 15.48, 16.32, 15.59, 17.43, 15.45, 17.30, 16.37…
## $ mass <dbl> 2.18, 2.01, 1.78, 1.98, 1.62, 2.59, 1.90, 2.55, 2.07, 2.26, 1…Saving files
Before we go too far it is often important to save the modified data
We can use the read_r package to do this with write_csv
# Saving files -----
# We can save the file we just read in using
# Saving dataframes -----
# lets say you have made a lot of changes and its now time to save the dataframe
write_csv(mm.df, "finalized_data/mm_output.csv")GGPlot
This script will go over a lot of the basics of creating graphs in GGPlot and later on we will go over how to do more specialized things. This is by no means a complete guide to GGPlot but will do most of the things that you will need to do in GGPlot. Any suggestions or recommendations of things to add would be welcome.
Graphing data
I feel that graphing is the key to all data analysis. If you can look at your data you can begin to see patterns that you may have predicted and want to test statistically. You will also be able to see outliers that exist that might affect resutls faster than looking at summary statistics.
Using proper GGPlot code you are supposed to have dat = , y = and x = ….
I have found that these are not necessary most of the time and we can talk about this later.
# GGplot uses layers to build a graph
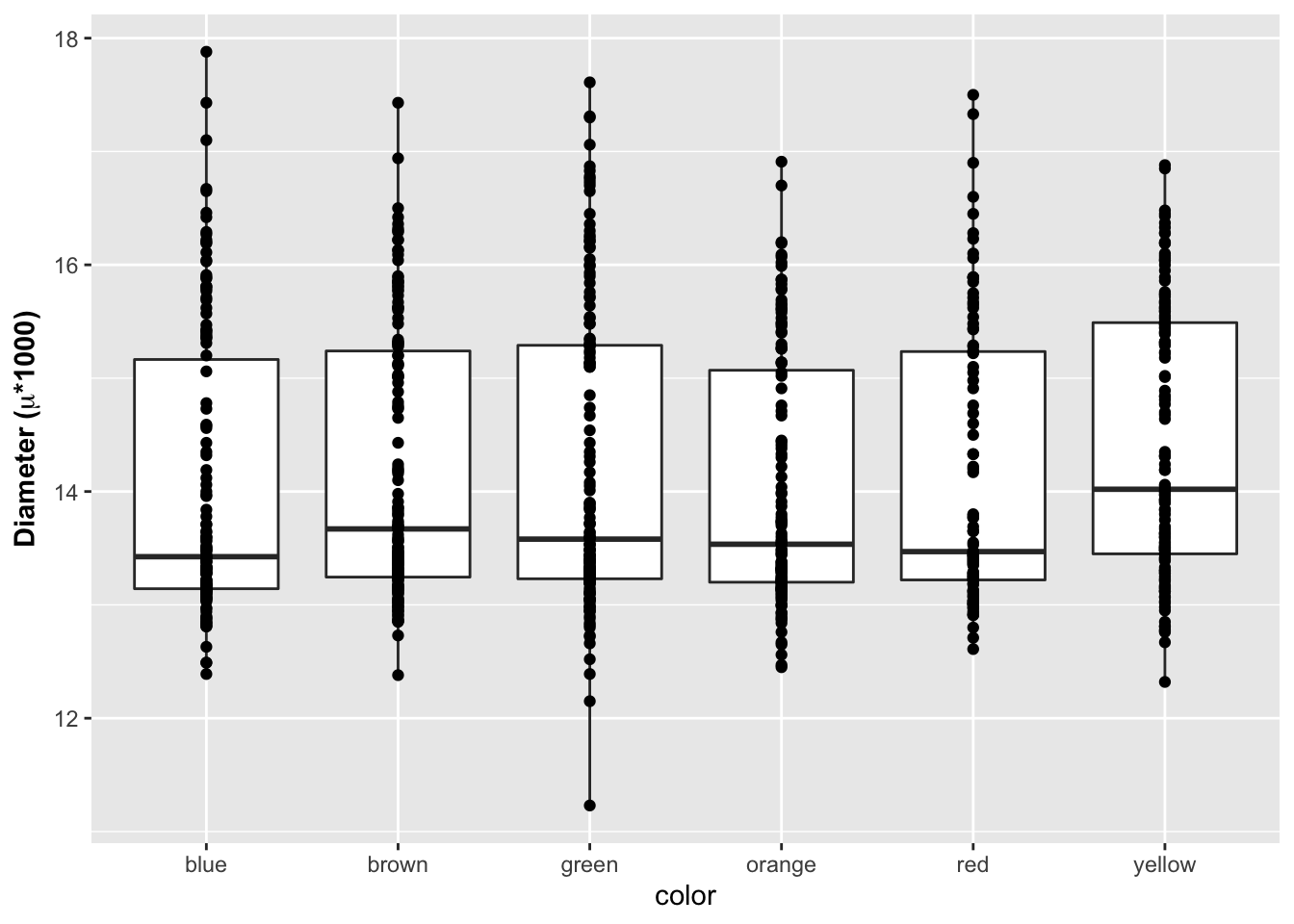
ggplot(data=mm.df, aes(x=color, y=diameter)) + # this sets up data
geom_point() # this adds a geometry to present the data from above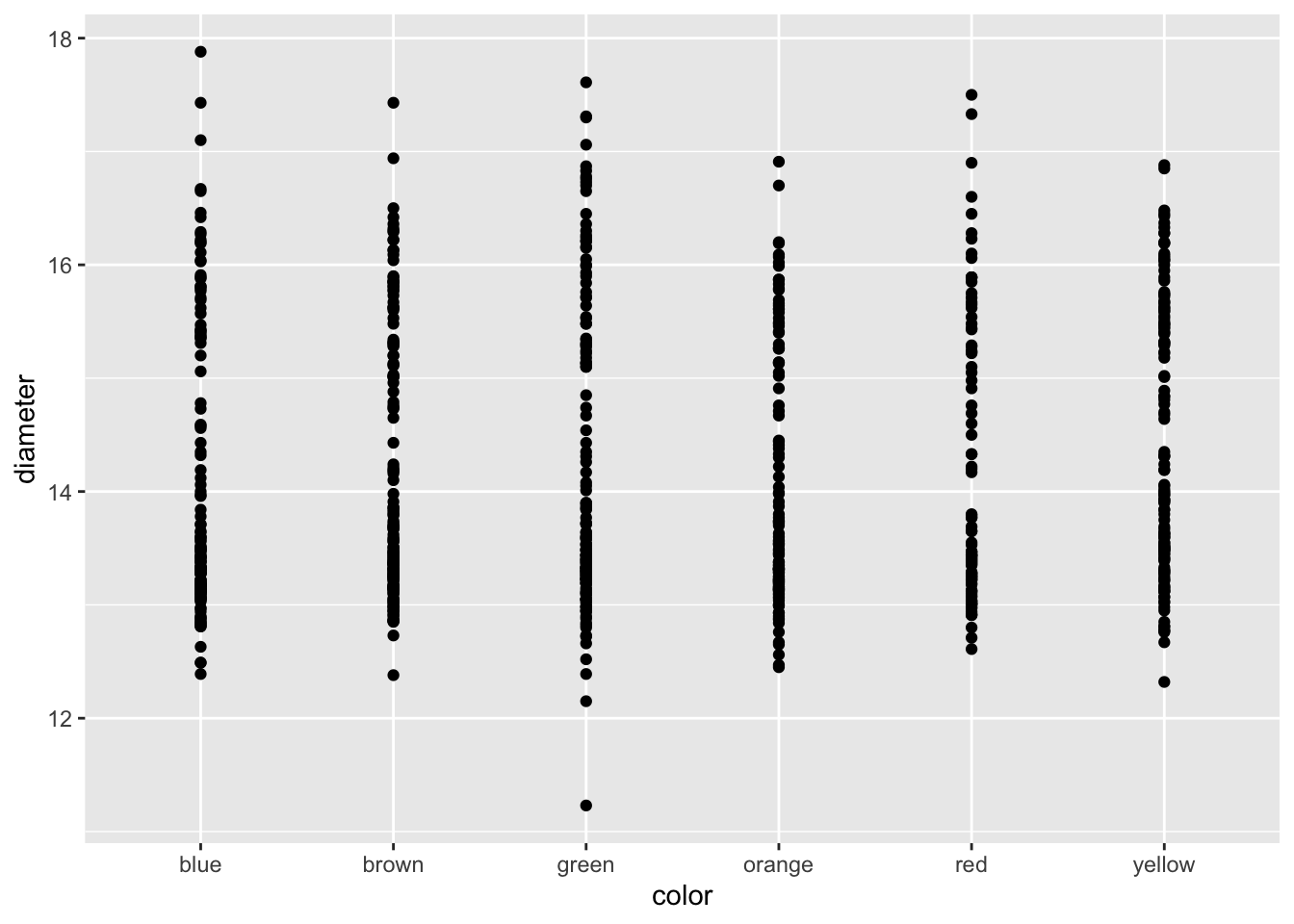
Because GGPlot builds things in layers you can add other geoms to the plot. Below you should try this code and see what happens when you put in + after geom_line() and then add geom_boxplot().
# Add geom_point() -----
# Add points to the graph below using geom_point()
ggplot(mm.df, aes(x=color, y=diameter)) +
geom_point() 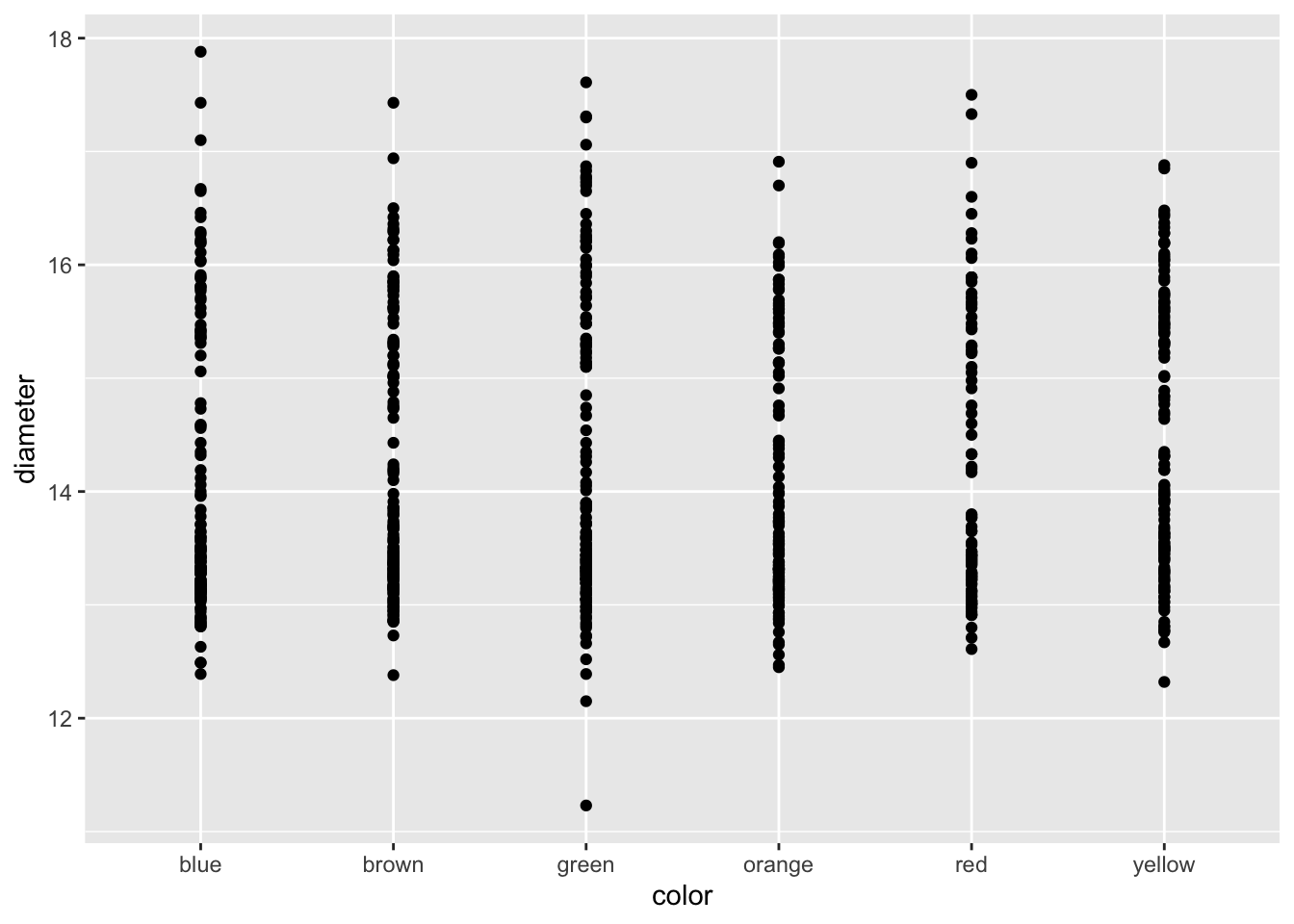
Adding axes labels
You can add in simple axes labels that are not formatted. Using the labs(x= " “, y =” ") statement. You can add in line breaks by putting in a \n in the statement that you have below.
# Adding axes labels ----
ggplot(mm.df, aes(x=color, y=diameter)) +
geom_boxplot() +
geom_point() +
labs(x = "Color", y = "Diameter")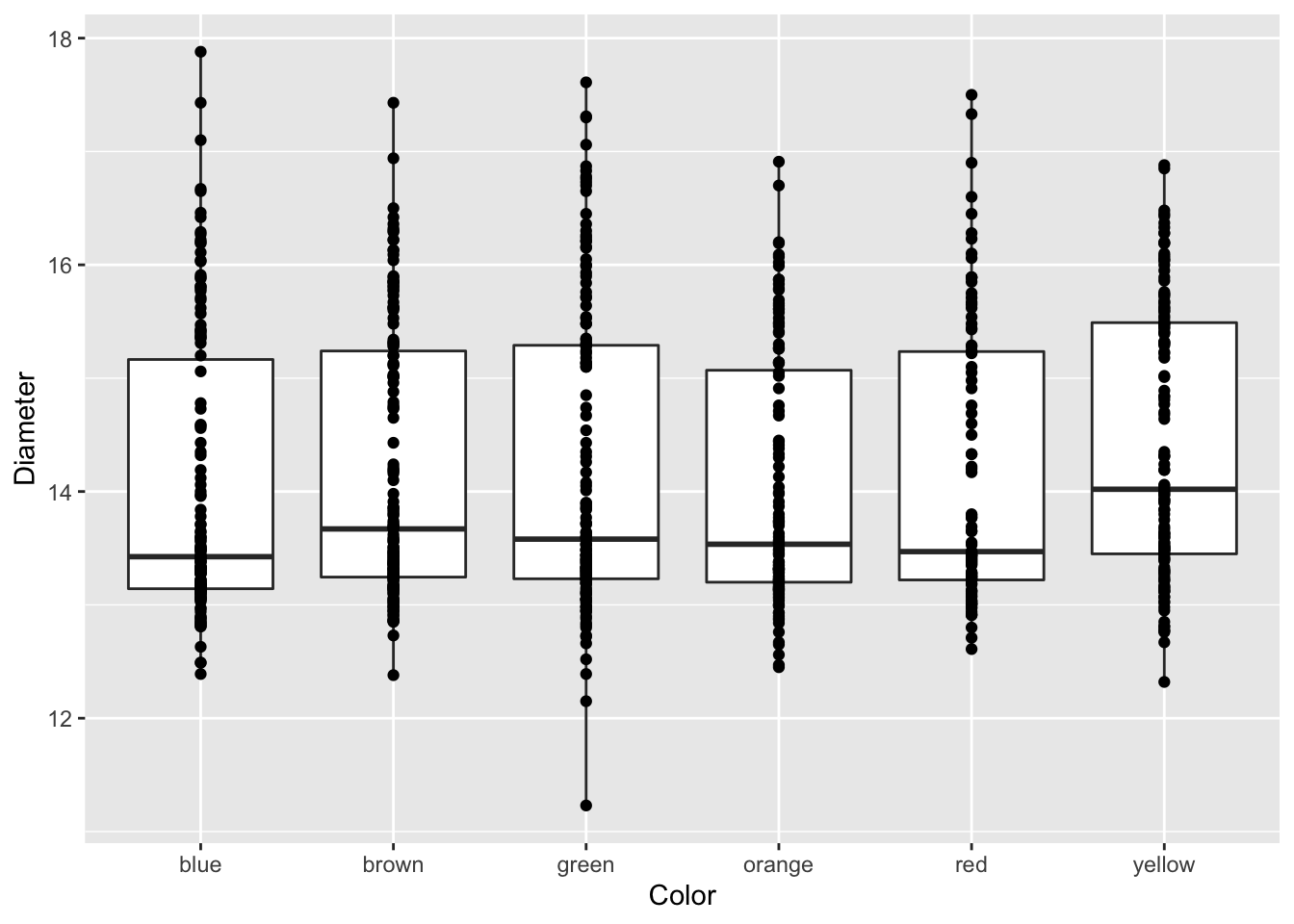
Formatted axes labels
What I find really nice is being able to create formatted axes labels. You can do this a few ways but I have found the that the expression statement works the best for my needs. You can add in a ~ to add a space between symbols and a * will connect things without a space.
# Label expressions -----
# Adding special formatting to labels
ggplot(mm.df, aes(x=color, y=diameter)) +
geom_boxplot() +
geom_point() +
labs(x = "color", y = expression(bold("Diameter ("*mu*"*1000)")))